Tidyverse and read in datas
Day 1
January 15, 2024
1 The tidyverse

The tidyverse
The tidyverse is an opinonated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures.
(www.tidyverse.org)
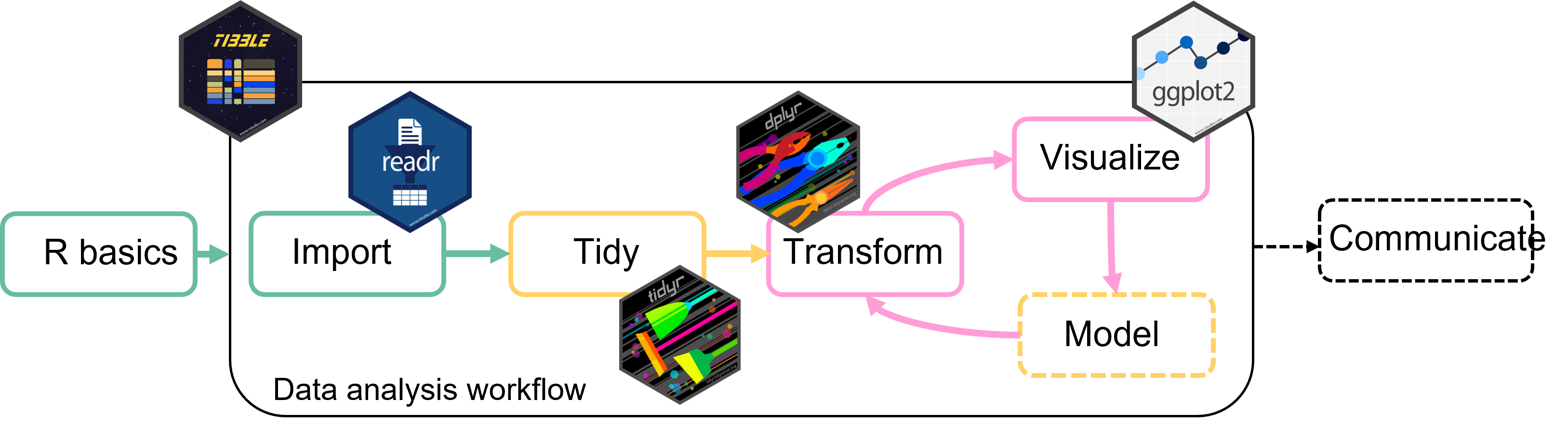
These are the main packages from the tidyverse that we will use:





Workflow data analysis
2 Import and export data with readr
Read files with read_*()
Specify number of lines to skip reading with skip
- Useful if you have metadata on top of the file
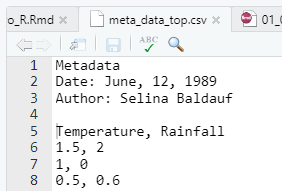
# without skipping first lines
read_csv(file = "data/meta_data_top.csv")# A tibble: 6 × 1
Metadata
<chr>
1 Date: June, 12, 1989
2 Author: Selina Baldauf
3 Temperature, Rainfall
4 1.5, 2
5 1, 0
6 0.5, 0.6 # skip meta data lines
read_csv(
file = "data/meta_data_top.csv",
skip = 4
)# A tibble: 3 × 2
Temperature Rainfall
<dbl> <dbl>
1 1.5 2
2 1 0
3 0.5 0.6Read files with read_*()
Specify whether the data has a header column or not with col_names
- Useful if you don’t have column names or you want to change them
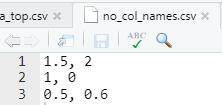
Read files with read_*()
Specify whether the data has a header column or not with col_names
- Useful if you don’t have column names or you want to change them
# First line expected to be column names
read_csv(file = "data/no_col_names.csv")# A tibble: 2 × 2
`1.5` `2`
<dbl> <dbl>
1 1 0
2 0.5 0.63 Import excel files
