library(dplyr)
library(tidyr)
library(ggplot2)
## theme for ggplot
theme_set(theme_classic())
theme_update(text = element_text(size = 14))Statistical tests
Day 5
January 19, 2024
Life expectancy
- simulate life expectancy of 100 people with a log-normal distribution
- we then compare the life expectancy of two groups (control, treatment) with a Wilcoxon test
No difference in life expectancy
p_values <- c()
for (i in 1:2000) {
x_control <- rlnorm(100, meanlog = log(75), sdlog = 0.12)
x_treatment <- rlnorm(100, meanlog = log(75), sdlog = 0.12)
p_val <- wilcox.test(x_control, x_treatment)$p.value
p_values <- c(p_values, p_val)
}
mean(p_values < 0.05)[1] 0.051Code
plotting_df <- tibble(p_values = p_values,
color = ifelse(p_values < 0.05, "significant", "non-significant"))
ggplot(plotting_df) +
geom_histogram(aes(p_values, fill = color), bins = 100,
breaks = seq(0, 1, 0.05)) +
scale_fill_manual(values = c("significant" = "red", "non-significant" = "grey")) +
labs(fill = "", x = "p-value")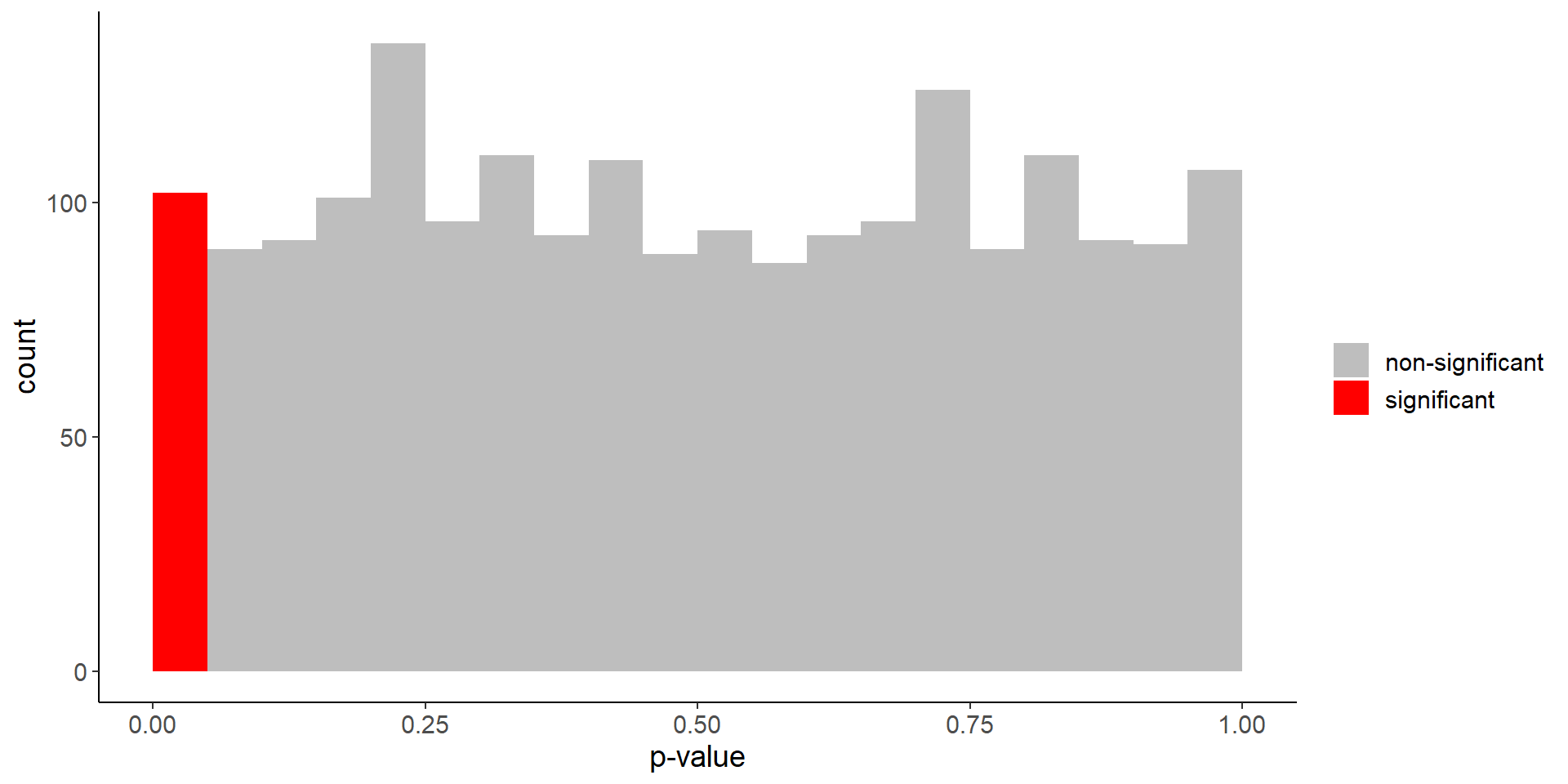
Difference in life expectancy
p_values <- c()
for (i in 1:2000) {
x_control <- rlnorm(100, meanlog = log(75), sdlog = 0.12)
x_treatment <- rlnorm(100, meanlog = log(77), sdlog = 0.12)
p_val <- wilcox.test(x_control, x_treatment)$p.value
p_values <- c(p_values, p_val)
}
mean(p_values < 0.05)[1] 0.317Code
plotting_df <- tibble(p_values = p_values,
color = ifelse(p_values < 0.05, "significant", "non-significant"))
ggplot(plotting_df) +
geom_histogram(aes(p_values, fill = color), bins = 100,
breaks = seq(0, 1, 0.05)) +
scale_fill_manual(values = c("significant" = "red", "non-significant" = "grey")) +
labs(fill = "", x = "p-value")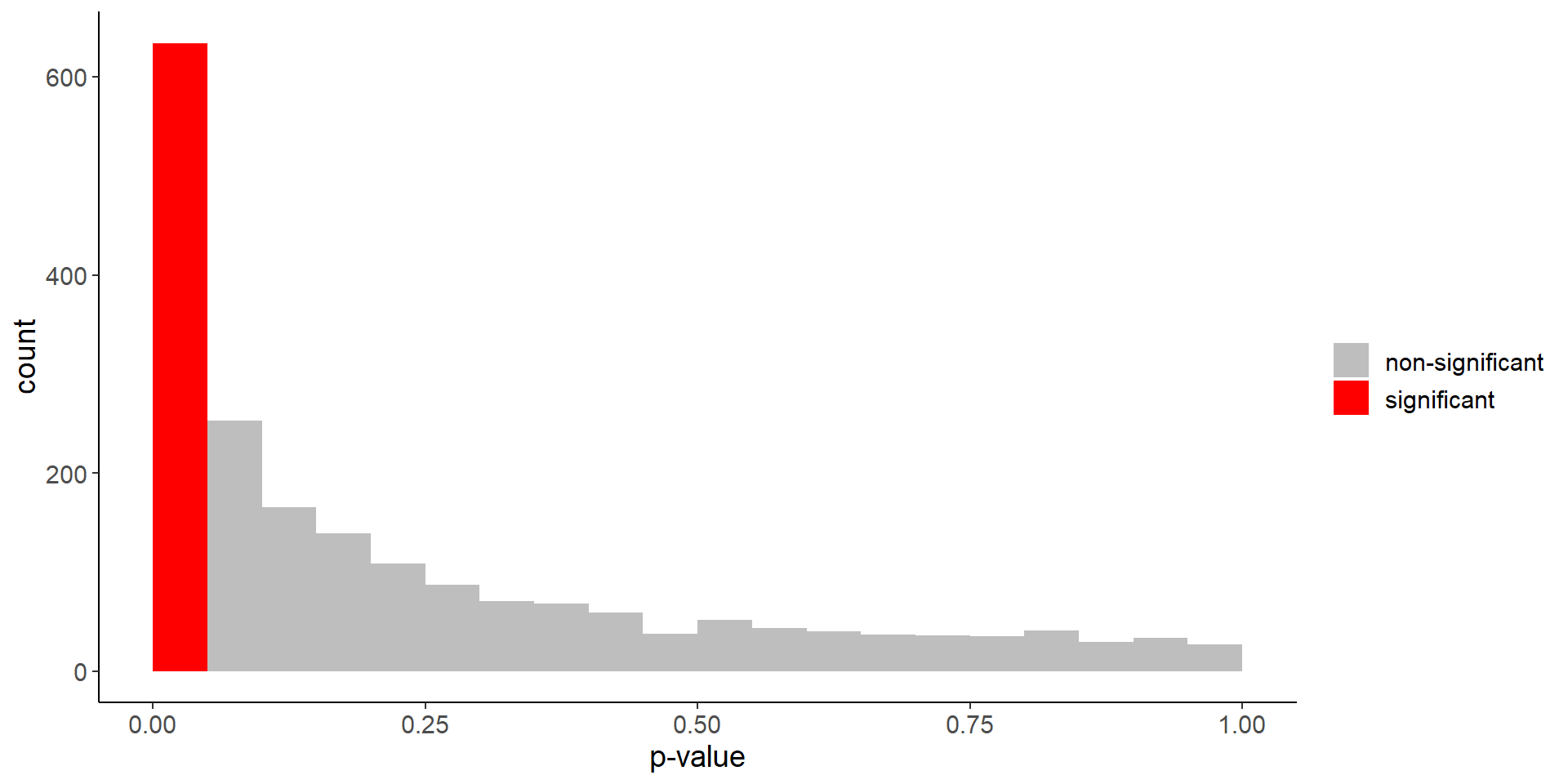
Difference in life expectancy
p_values <- c()
for (i in 1:2000) {
x_control <- rlnorm(10, meanlog = log(75), sdlog = 0.12)
x_treatment <- rlnorm(10, meanlog = log(77), sdlog = 0.12)
p_val <- wilcox.test(x_control, x_treatment)$p.value
p_values <- c(p_values, p_val)
}
mean(p_values < 0.05)[1] 0.061Code
plotting_df <- tibble(p_values = p_values,
color = ifelse(p_values < 0.05, "significant", "non-significant"))
ggplot(plotting_df) +
geom_histogram(aes(p_values, fill = color), bins = 100,
breaks = seq(0, 1, 0.05)) +
scale_fill_manual(values = c("significant" = "red", "non-significant" = "grey")) +
labs(fill = "", x = "p-value")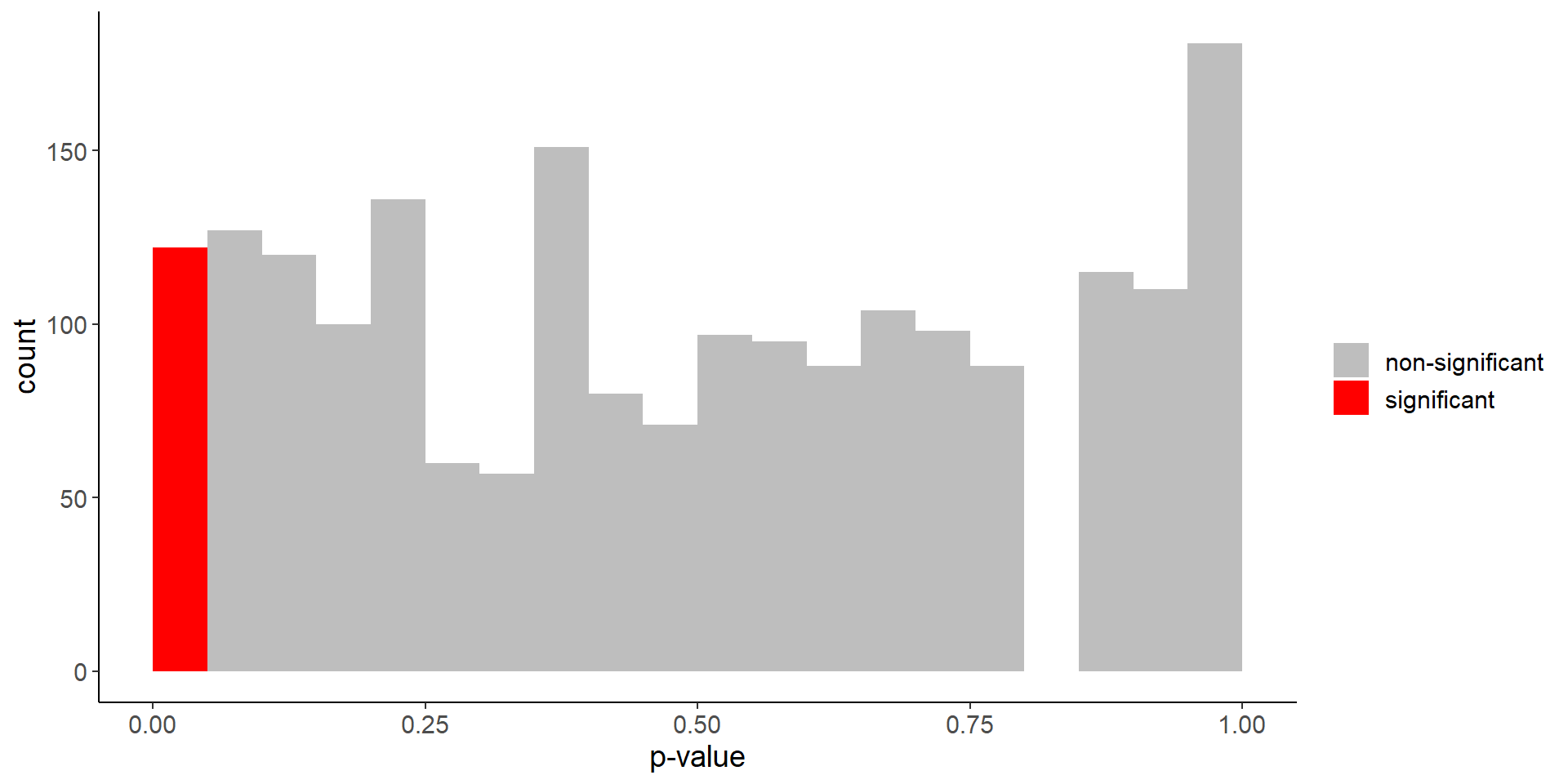
Difference in life expectancy
p_values <- c()
for (i in 1:2000) {
x_control <- rlnorm(100, meanlog = log(75), sdlog = 0.12)
x_treatment <- rlnorm(100, meanlog = log(80), sdlog = 0.12)
p_val <- wilcox.test(x_control, x_treatment)$p.value
p_values <- c(p_values, p_val)
}
mean(p_values < 0.05)[1] 0.9595Code
plotting_df <- tibble(p_values = p_values,
color = ifelse(p_values < 0.05, "significant", "non-significant"))
ggplot(plotting_df) +
geom_histogram(aes(p_values, fill = color), bins = 100,
breaks = seq(0, 1, 0.05)) +
scale_fill_manual(values = c("significant" = "red", "non-significant" = "grey")) +
labs(fill = "", x = "p-value")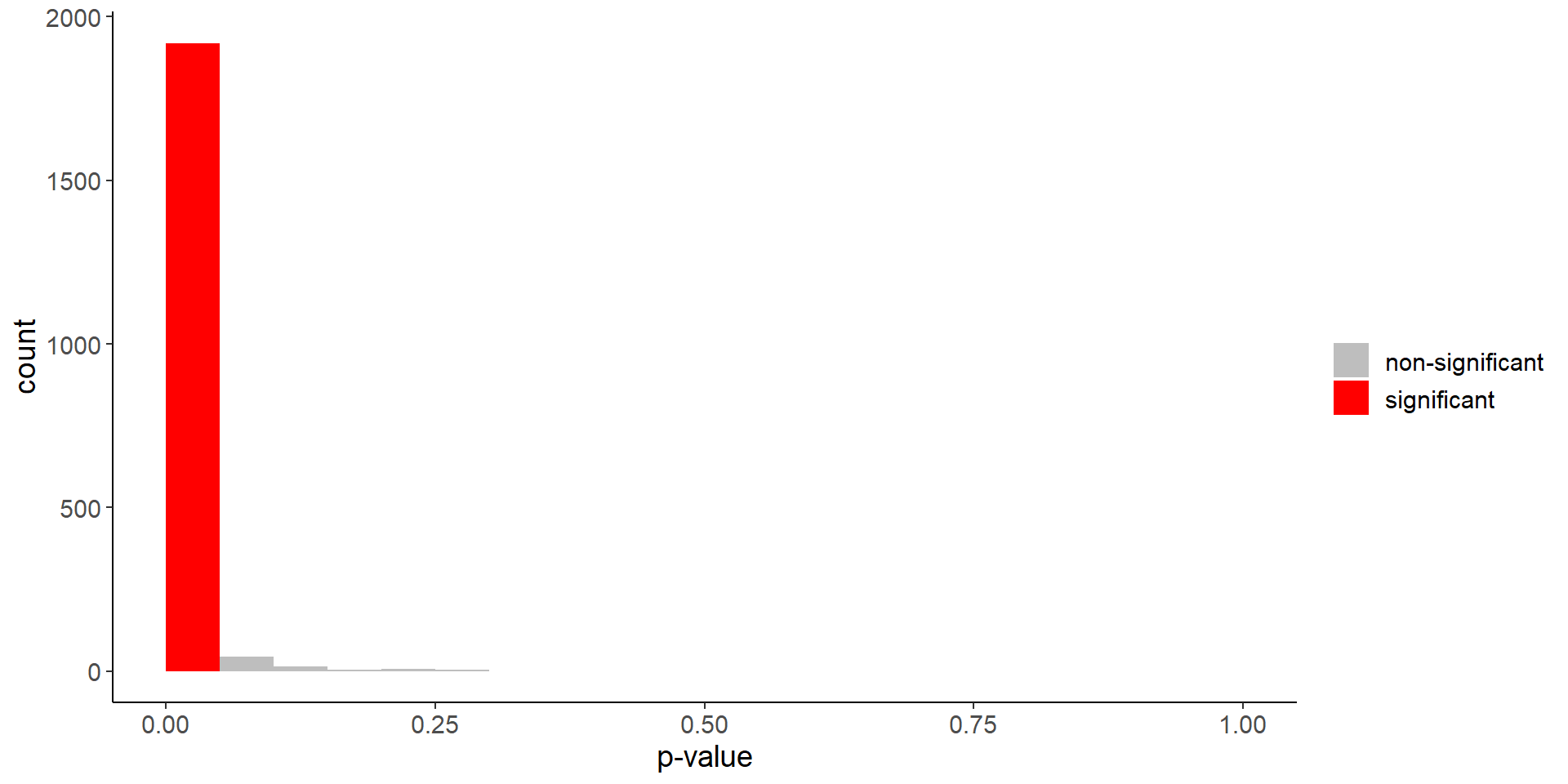
4 Errors in statistical tests

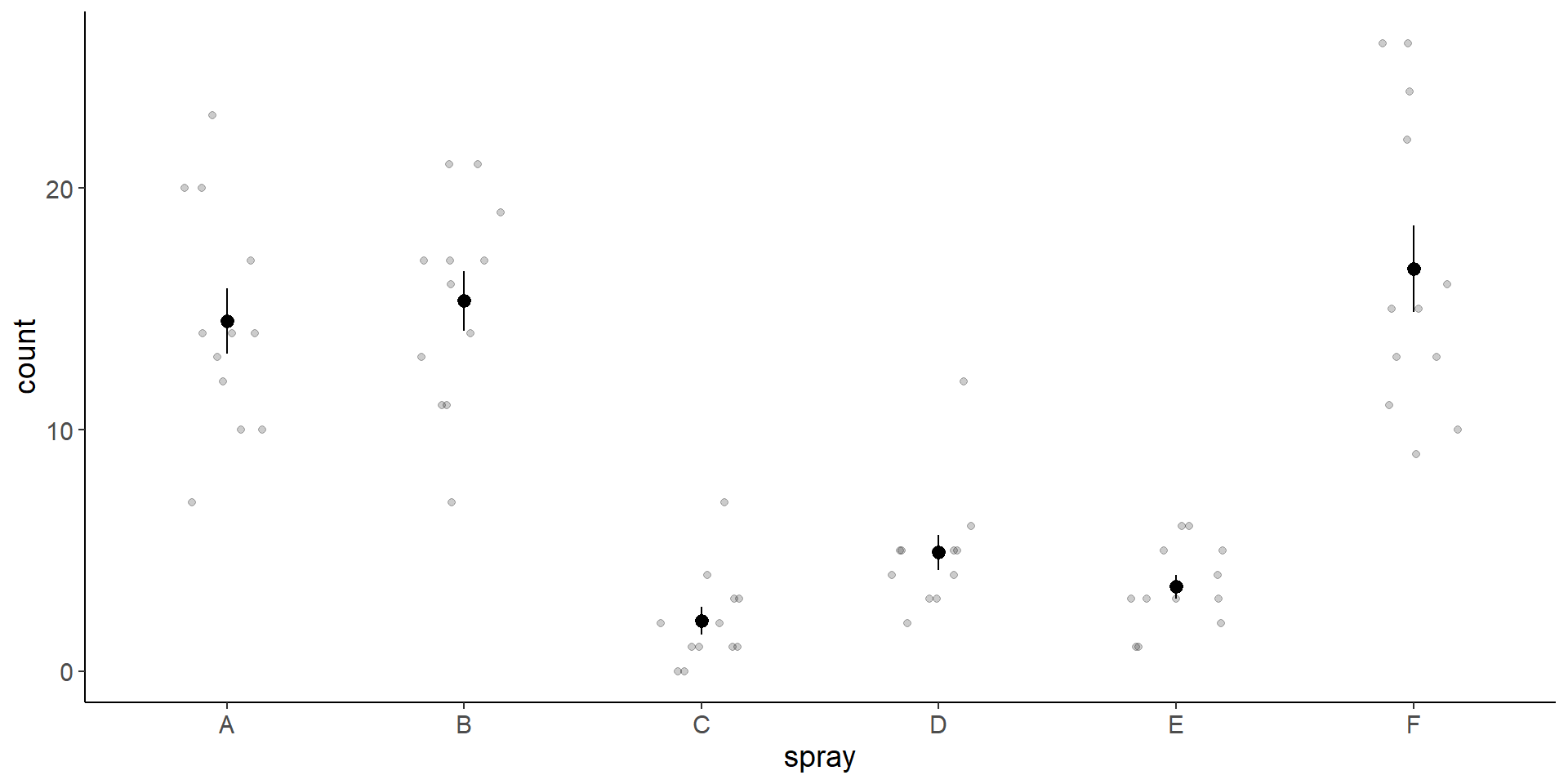
Note: Plot mean +- se using stat_summary
One way to plot the results is to plot mean and standard error of the mean:
ggplot(InsectSprays, aes(x = spray, y = count)) +
geom_jitter(width = 0.2, height = 0, alpha = 0.2) +
stat_summary(fun.data = mean_se)