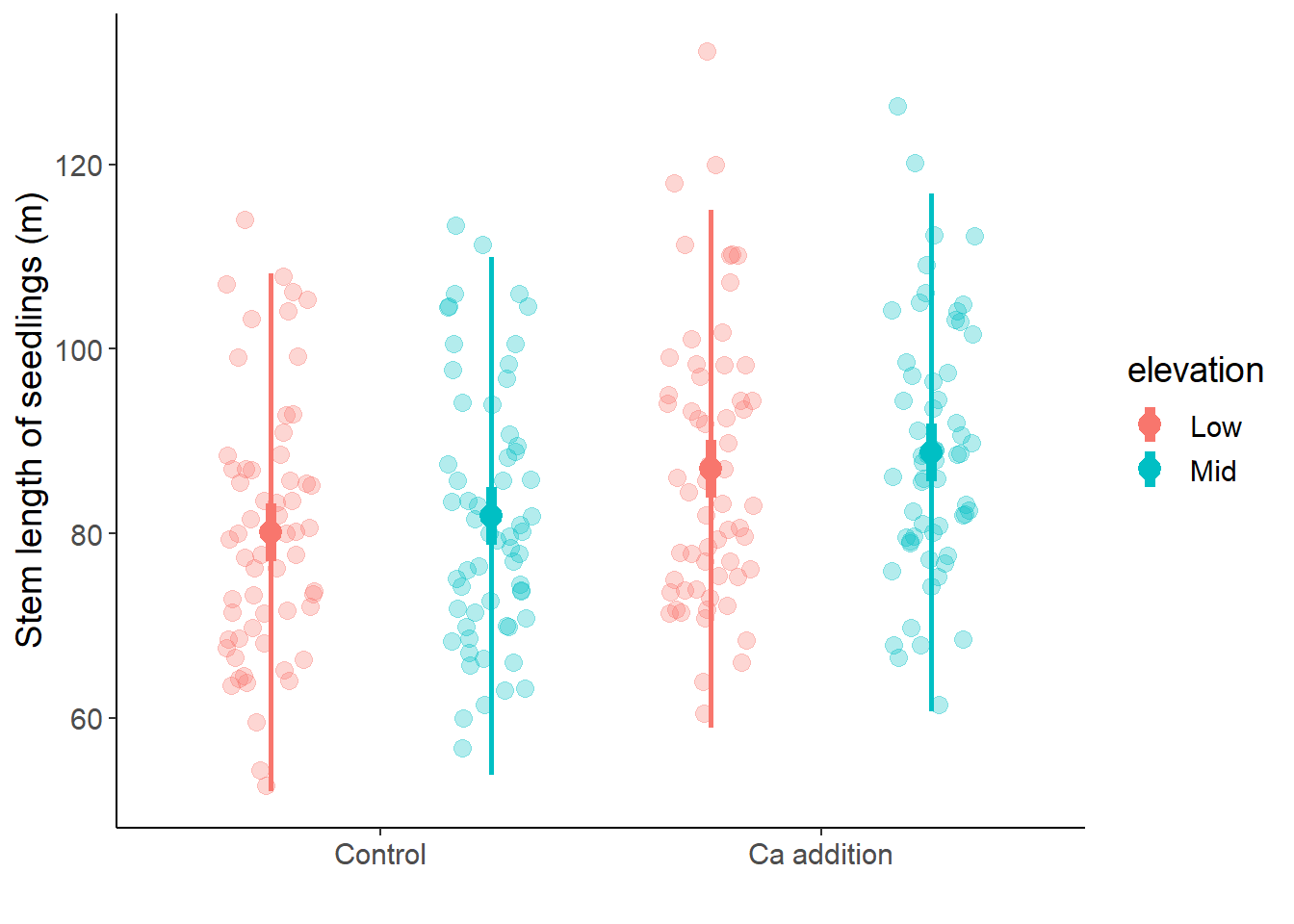
## load packageslibrary(readr)library(dplyr)library(tidyr)library(ggplot2)library(ggfortify)## theme for ggplottheme_set(theme_classic())theme_update(text =element_text(size =14))## read datadf_maples_prep <-read_csv("data/06_maples.csv")## filter out missing values and rename factor levels## and select columnsdf_maples <- df_maples_prep %>%mutate(calcium_addition =factor(watershed, levels =c("Reference", "W1"),labels =c("Control", "Ca addition"))) %>%select(stem_length, elevation, calcium_addition)df_maples
# A tibble: 240 × 3
stem_length elevation calcium_addition
<dbl> <chr> <fct>
1 86.9 Low Control
2 114 Low Control
3 83.5 Low Control
4 68.1 Low Control
5 72.1 Low Control
6 77.7 Low Control
7 85.5 Low Control
8 81.6 Low Control
9 92.9 Low Control
10 59.6 Low Control
# ℹ 230 more rows
The estimate of the interaction is quite low. The adjusted R² is lower for the second model. Therefore, if you want to make good predictions it is better to use the first model.